

前回までのおさらい
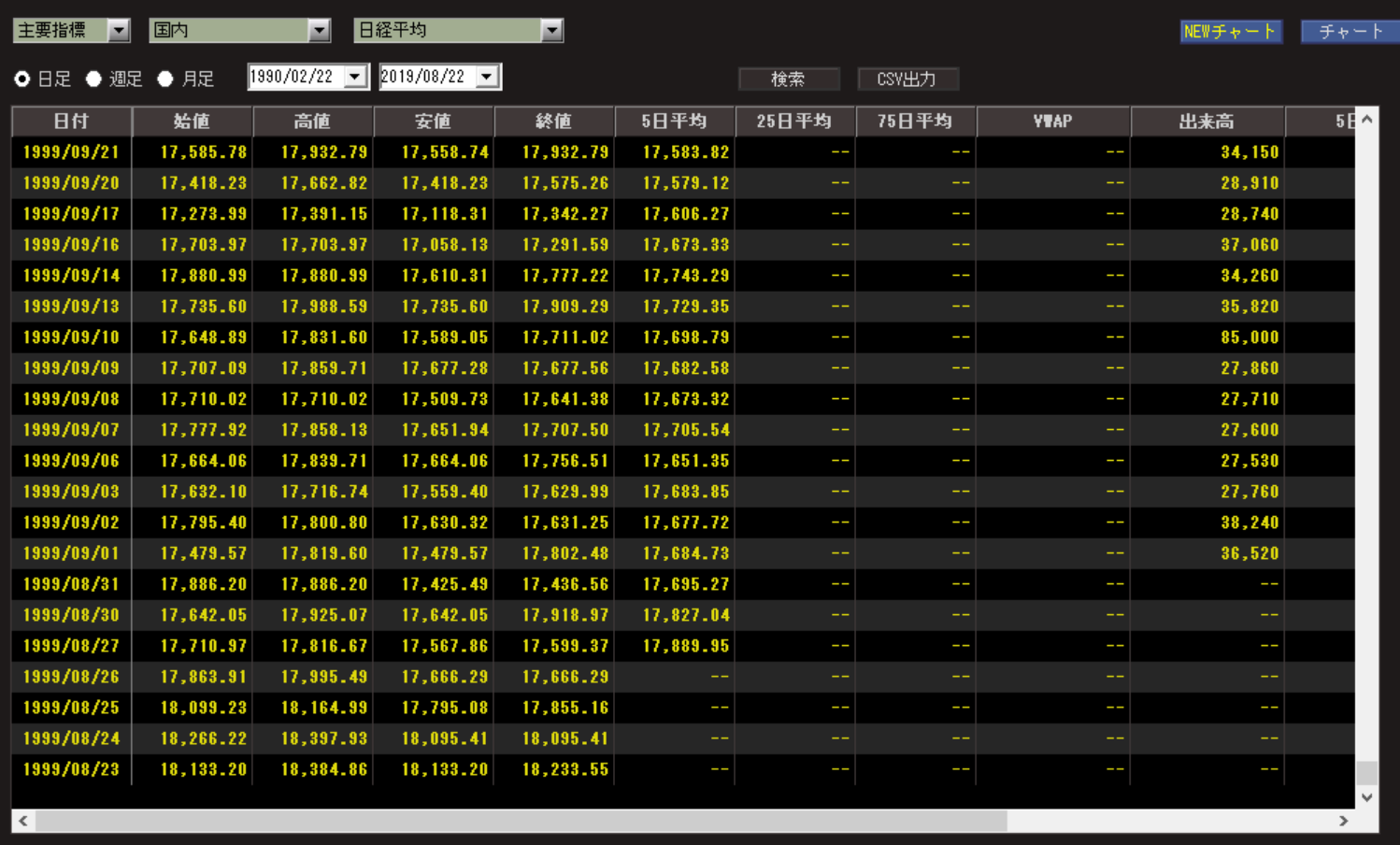
SBIの株価データをもとに、過去20年分の始値・高値・安値・終値をゲットすることができました。
そこで今回は、そのデータをもとに、株価の予測を話題の機械学習・ディープラーニングを使ってやっていきたいと思います。
そもそも機械学習とは
機械学習(きかいがくしゅう、(英: Machine learning、略称: ML)は、明示的な指示を用いることなく、その代わりにパターンと推論に依存して、特定の課題を効率的に実行するためにコンピュータシステムが使用するアルゴリズムおよび統計モデルの科学研究である。 (wikipidia)
つまり、データをもとに、コンピュータが学習して、その学習をもとに予想や分類を行うものです。
一方でディープラーニングとは
ディープラーニング(英: deep learning)または深層学習(しんそうがくしゅう)とは、(狭義には4層以上[1][注釈 1]の)多層のニューラルネットワーク(ディープニューラルネットワーク、英: deep neural network; DNN)による機械学習手法である[2]。深層学習登場以前、4層以上の深層ニューラルネットは、局所最適解や勾配消失などの技術的な問題によって十分学習させられず、性能も芳しくなかった。しかし、近年、ヒントンらによる多層ニューラルネットワークの学習の研究や、学習に必要な計算機の能力向上、および、Webの発達による訓練データ調達の容易化によって、十分学習させられるようになった。その結果、音声・画像・自然言語を対象とする問題に対し、他の手法を圧倒する高い性能を示し[3]、2010年代に普及した[4]。 (wikipidia)
難しいですね。僕もはじめのころ全くわかりませんでした。
かみ砕いていうと、『データをもとに、コンピュータが学習して、その学習をもとに予想や分類を行う』
ここまでは機械学習と同じです。というか、ディープラーニングは数ある機械学習中の一つなのです。
『人間』の中に『のび太君』がいるように『機械学習』の中に『ディープラーニング』がある、ということですね。
そして、特筆すべきは、『それぞれのデータの重要度を少しずつ調整し、一番予想の制度が高くなるようチューニングを行う』ということです。
例えば、『学校の欠席者』を予想したいとします。用意したデータは
①『その日の気温』
②『その日の給食のメニュー』
の2つだとします。このデータ、どちらが重要に感じますか?
私は①の方が欠席者を予想する上で大切なデータだと思います。だから、①の方の重要度を90%、②もメニューで左右される人がいるかもしれないので10%くらいかなぁ・・。と予想してみます。
この重要度を変更することで、予想が微妙に変わってくるのです。
でももしかしたら給食のメニューの影響力がもっと少ないかもしれないし、多いかもしれませんよね。
そこでディープラーニングが役に立つんです。
①の重要度を80%、②を20%で予想。結果が90点
①の重要度を95%、②を5%。結果が95点
・・・・
と数多くの重要度の変更をパソコンが自動で行い、一番適した重要度を選んでくれるんです。
話を戻して、株価に機械学習(ディープラーニング)を用いる。
予想するためにはデータが必要になります。おそらくこのデータ選びが重要になってくるのではないかと思います。
株価の予想のためのデータとしていくつか考えられますね。例えば『日経平均』『前日比』『出来高』など、いくつもあるはずです。データがあればあるほど、機械学習にとってはメリットになるはずです。
しかし、あるサイトを見てみると『機械学習は株価の予想には使いづらい』とありました。時事問題やIRなど、思ってもみないことで大きく株価が上下することが理由に挙げられていました。
それをこれまでは人間が一つ一つ見て、予想を行って株の売買を行っていました。また、データのみを見る『テクニカル分析』という手法もあります。もし何らかの法則性があるのであれば、十分機械学習で戦えるのではないかと判断しました。
次回から具体的にデータの選別や機械学習の方法を書いていきます。
まだ検証等行っていないので、気長にお待ちください。
過去記事はこちら

コメント
続き、まってます!